什么是英特爾傲騰技術?
無晶體管設計數據按位級別寫入,因此每個單元的狀態可以獨立于其他單元被改變為0或1
英特爾傲騰Pmem和SSD填補數據中心計算和存儲間的差距

測試背景
由于Redis實例規模比較大45000+,使用服務器數量多2000+,而且使用內存存儲成本相比磁盤要高很多,基于Redis集群進行現狀分析,針對以下集群決定使用傲騰AEP存儲進行成本優化。
1.請求量低的小集群非常多,部署比較分散,服務器資源成本高。
2.大容量集群每次申請200G到2T容量不等,使用服務器數量多。
傲騰AEP上線需要做什么
傲騰AEP性能如何
首先性能測試,整體來講跟純內存相比有10%左右的損耗,測試數據如下。目前我們在該機型僅支持小集群、大容量的業務,目前不存在性能問題。
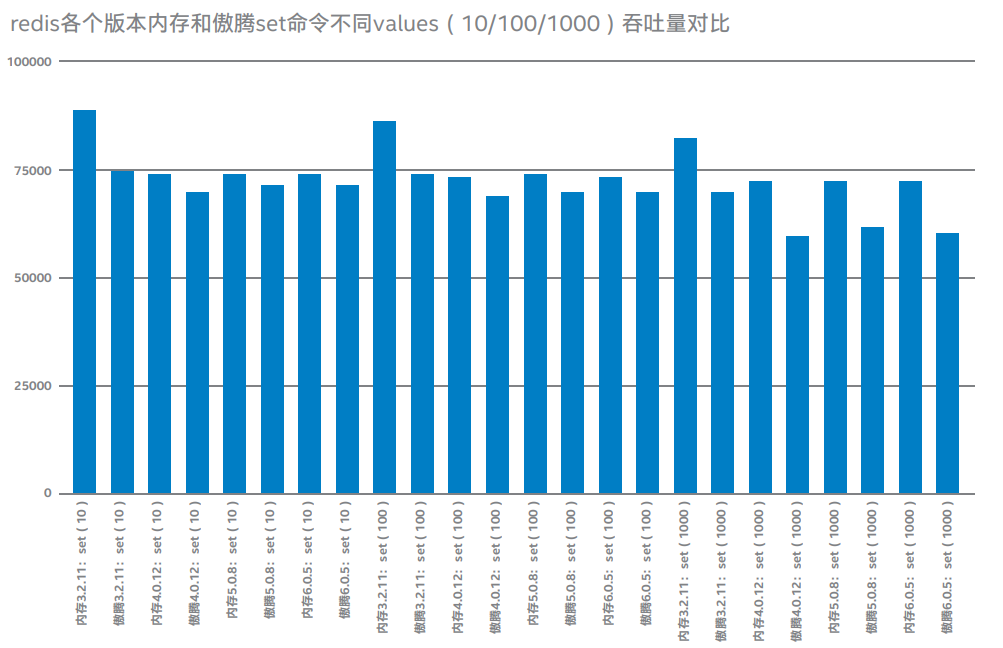
說明:上圖為當Redis單進程cpu負載80%左右的情況下,在內存和傲騰不同存儲上分別運行在不同版本3.2.11、4.0.12、5.0.8、6.0.5,當set命令value為10、100、1000字節每秒處理請求個數壓測結果對比。
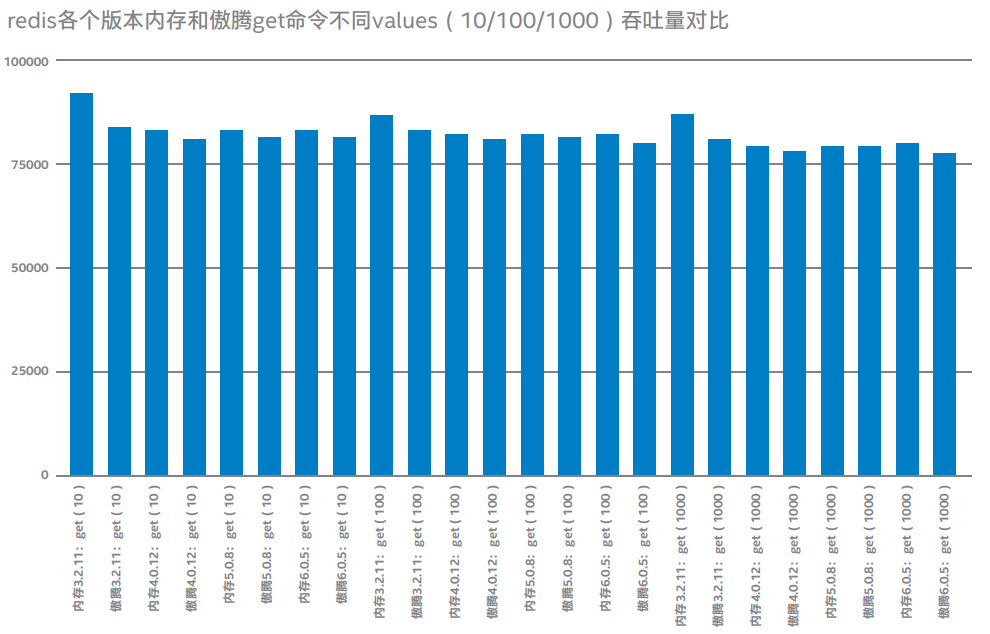
說明:上圖為當Redis單進程cpu負載80%左右的情況下,在內存和傲騰不同存儲上分別運行在不同版本3.2.11、4.0.12、5.0.8、6.0.5,當get命令value為10、100、1000字節每秒處理請求個數壓測結果對比。
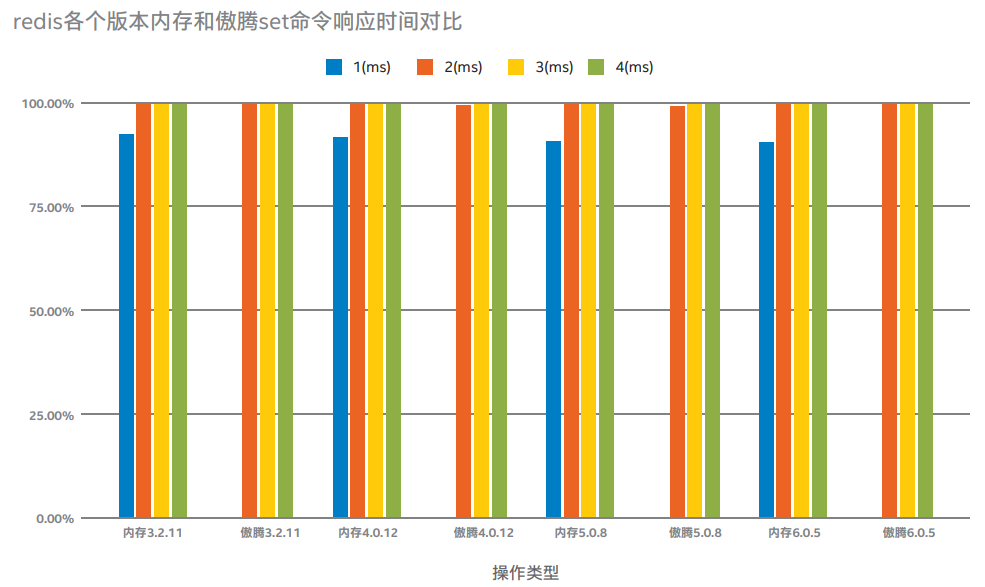
說明:上圖為當Redis單進程cpu負載80%左右的情況下,在內存和傲騰不同存儲上分別運行在不同版本3.2.11、4.0.12、5.0.8、6.0.5,當set命令value為10、100、1000字節響應時間分別為1、2、3、4毫秒的百分比壓測結果對比。
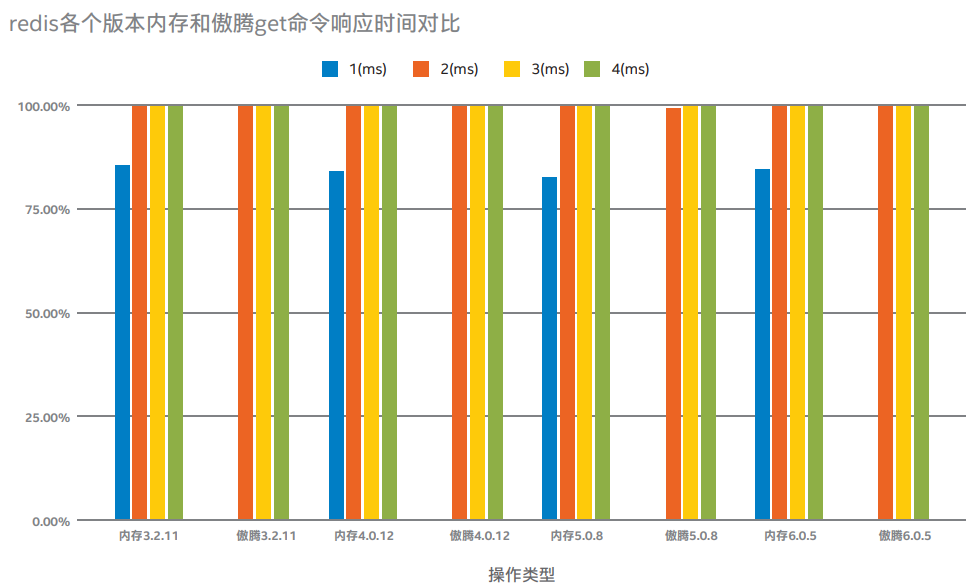
說明:上圖為當Redis單進程cpu負載80%左右的情況下,在內存和傲騰不同存儲上分別運行在不同版本3.2.11、4.0.12、5.0.8、6.0.5,當get命令value為10、100、1000字節響應時間分別為1、2、3、4毫秒的百分比壓測結果對比。
密集部署調度是否能打散
1.redis集群1個節點下主從不在同一個機柜組。
2.redis內存利用率大于50%不再調度新實例
3.一個機柜組承載每個集群不超過25%的實例數。
4.擴容k8s集群中node后新增實例的打散依然符合以上規則。
密集部署宕機業務影響范圍
1.業務恢復時間從實例不可用到域名切換完成耗時20~40s之間。
2.拓撲恢復時間完全自動化,DBA關注進度就好,宕機服務器500+G內存恢復需要30min左右。
密集部署遇到的問題
1>.整點cpu高,慢日志數量增多,業務出現規律性超時。
原因:
1.每個docker容器整點執行收集Redis客戶端連接,遇到客戶端連接多的情況尤為嚴重。
2.每個docker容器整點執行收集Redis元信息的任務。
3.每個docker容器整點執行anacron任務。
解決方案:
1.降低定時任務收集客戶端連接的頻率。
2.隨機打散定時任務的執行時間。
3.去掉不必要的定時任務。
2>.sentinel高可用服務自動切換部分失敗。
原因:
1.sentinel服務線程數不夠,丟棄部分待處理任務。
2.sentinel元信息更新失敗問題。
解決方案:
1.優化sentinel服務線程數。
2.優化更新sentinel元信息的版本控制。
3>.sentinel高可用服務異常切換慢。
原因:
1.異常檢測周期長。
2.域名切換耗時高。
解決方案:
1.異常檢測周期由原來30s降低到10s。
2.優化域名切換接口索引缺失問題由原來平均30s降低到3s。
4>.Redis負載高,操作系統卡頓。
原因:
1.docker容器管理Redis進程,sentinel-agent組件沿用物理機部署版本,線程數過高導致操作系統卡。
2.每個docker容器部署了repl-agent組件。
3.每個docker容器的cadvisor監控項過多。
解決方案:
1.優化sentinel-agent組件降低線程數。
2.下線repl-agent棄用組件。
3.優化cadvisor監控項數量
5>./var目錄容量滿出現Redis所在容器被驅逐。
解決方案:
1.將coredump日志記錄到較大分區。
2.優化各個分區容量的使用的報警等級。
6>.Redis宿主機重啟后二次調度,導致數據異常。
解決方案:
1.任務原因導致的宿主機宕機,自動進行調度隔離。
管理方式變更
1>.Redis資源申請 1.目前可以做到Redis資源分鐘級別交付。
2>.增加異常診斷
1.基于Redis、操作系統,中間件層快速聚合分析到歷史時間段的異常指標。生成集群診斷報告。
2.通過獲取Redis實時monitor日志,分析出熱點數據,輸出熱點報表信息。
3>.異常處理預案
1.增加了sentinel服務異常后宕機批量切換工具。
2.增加了主從同時宕機批量從異地備份機恢復數據的工具。
4>.增加集群畫像
1.集群列表頁關聯業務組,劃分權限,只顯示各自歸屬集群,方便業務方查看。
2.業務方更詳細了解集群基礎信息(架構、分片、機房等)和性能信息(訪問量、容量等指標的實時統計和天級統計)。
3.基礎數據完整和準確,有效實施后續自動化功能建設。
4.實時統計、天級統計信息可定時產出報表,分析低訪問量、慢查詢多等集群。
5.集群信息完整,出問題時可以快速定位業務方、訪問源服務、關聯申請原工單、操作類型統計等維度方便排查。
階段工作成本對比

總結
1.非核心業務可以先上AEP,如果性能不夠再遷移到純內存服務器上。
2.目前存量小實例繼續進行遷移。
3.性能和TCO優勢分析: 英特爾? 傲騰? 數據中心級持久內存在新的推薦異構存儲系統和升級后 的Redis 服務中,不僅有著與 DRAM 內存相近的性能表現,其大容量 和非易失性還可幫助實現更優的可用性;通過不同的硬件組合,為不 同應用場景下的存儲需求提供高性能,高可擴展、安全可靠以及低 TCO的解決方案;在滿足應用性能需求的同時,內存的采購成本還得 到顯著降低,并減少了集群所需的節點數量,進而降低了TCO。
責任編輯:胡金鵬



